西华大学计算机与软件工程学院 610039
摘要:恶意软件是一种被设计用来对目标计算机造成破坏或者占用目标计算机资源的软件,传统的恶意软件包括蠕虫、木马等。这些恶意软件严重侵犯用户合法权益,甚至将为用户及他人带来巨大的经济或其他形式的利益损失。传统的恶意软件检测方法主要有特征码检测、行为检测等,此类方法对于已知的恶意程序有较高的准确率,但是对于未知的恶意程序表现较差,采用机器学习以及数据挖掘技术可以有效地提高对于恶意软件检测的准确率。本文各种文件分析,用词袋模型提取API序列作为特征,以随机森林作为模型进行学习,从而对程序进行检测,最终获得了较好的检测结果。
关键字:恶意软件检测;机器学习;词袋模型;API序列;随机森林
随着互联网时代的飞速发展,网络已经进入人们日常生活的方方面面,给人们带来了非常便捷的服务。与此相对应,网络中传输和存储的各种数据也呈指数增长。而网络具有开放性和互联性的特点,非常容易受到网络黑客的入侵和攻击。近十年来,随着计算机技术的飞速发展,计算机病毒、黑客入侵等安全事件频繁发生。一旦发生数据泄露等安全事件,不仅个人,国家也将遭受巨大的财产损失和安全威胁。
在诸多入侵和攻击手段中对于网络安全威胁最大的是各种各样的恶意软件,恶意软件又称“流氓软件”,一般是指通过网络、便携式存储设备等方式传播,故意造成隐私或机密数据泄露、系统损坏(包括但不限于系统崩溃等),个人电脑、服务器、智能设备、计算机网络等出现数据丢失等意外故障和信息安全问题,并试图使用各种方式防止用户删除,如“流氓”软件。
2 恶意程序检测研究现状
目前的恶意软件检测方法主要有特征码检测、行为检测等,两者的缺陷如下:
特征码检测,其最大的缺陷在于需要维护巨大的特征码库,因为需要与数据库中已知的特征码进行对比,因此特征码检测技术无法检测未知攻击,而且恶意软件制造者也能通过反汇编,逆向工程等手段修改特征码从而绕过检测。
行为检测,行为检测首先需要人预先对行为进行定义即书写规则,然后在检测过程中将软件的行为与规则进行匹配,规则既可以是黑名单模式也可以是白名单模式,但是和特征码检测一样,都需要预先设定好,而对于未知的恶意程序,模式可能不会匹配或者被恶意软件制造者用技术手段进行绕过。
3 机器学习
机器学习是人工智能的一个分支。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。因为学习算法中涉及了大量的统计学理论,机器学习与推断统计学联系尤为密切,也被称为统计学习理论。
4 基于机器学习的恶意程序检测
为了改进传统检测方法中的缺陷,采用机器学习算法,可以自动的对于特征进行提取,而非编程人员手动书写规则。通过机器学习算法,既提高了对于未知病毒的检测效果,同时也更难以被常规的免杀手段绕过。
在机器学习和传统的检测方法基础上我们设计了一种基于机器学习的恶意程序检测方法,如图1所示,检测过程主要分为三大模块:数据采集,数据预处理处理,模型学习及分类预测。
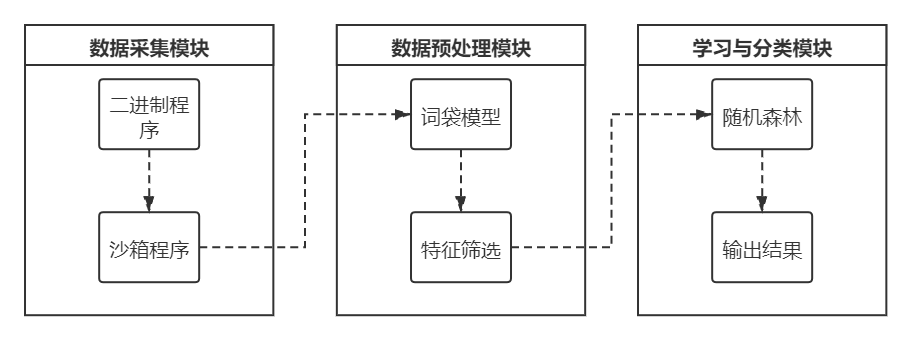
图1 基于机器学习的恶意程序检测方法
主要完成数据采集工作,首先通过爬虫或者其他手段获取各个类型的二进制程序,之后通过沙箱程序,得到二进制程序的API调用序列,将调用序列保存为CSV(逗号分隔值)文件,输入预处理模块进行处理。
预处理模块需要将采集到的API调用序列处理,变成机器学习模型可以直接处理的数据。
学习模型使用随机森林模型,学习及分类模块包括以下几个主要的函数及类:决策树类,随机森林类,计算基尼指数,选择最优划分属性,自助法抽样。
其中决策树类,包含计算基尼指数和选择最优划分属性这两个主要的函数,随机森林类在决策树类的基础上使用自主抽样法,训练得到的决策树进行简单投票最终集成为随机森林,最终随机森林算法对预处理得到的数据进行机器学习,并最终输出分类结果。
训练数据来源于阿里云天池数据平台,是Windows平台下二进制程序经过Cuckoo Sandbox提取得到的API调用序列,该数据集文件类型包括调用记录近9000万次,文件1万多个,文件类型包括正常文件、勒索病毒、挖矿程序、DDoS木马、蠕虫病毒、感染型病毒、后门程序、木马程序。
5.2 评价指标
评价指标我们使用分类任务最常见的四个指标:查全率(Precision),查准率(Recall),F1,以及精度(Accuracy)。
5.3 实验结果
实验结果如表1所示,从准确率上看,随机森林显著高于决策树,每个类别的查准率、查全率,以及F1也明显有优势,可见集成模型的性能要优于单个分类器模型。
从随机森林模型的性能表现来看,样例数较多的类别在查准率、查全率和F1上的表现都要明显高于样例数较少的类,对于这种不平衡类的划分,如果想要进一步提高性能,可以考虑使用欠采样或者过采样技术解决。
表1 实验结果
模型 | Precision | Recall | F1 | Accuracy |
决策树 | 0.73 | 0.70 | 0.71 | 0.83 |
随机森林 | 0.81 | 0.75 | 0.78 | 0.89 |
6 结语
随着互联网的高速发展,网络安全问题已经成为一个不可回避的问题。随着国家一系列网络安全法律法规的出台,网络安全已经得到极大的关注。社会对于网络安全人才的需求也越来越大,同时也需要更加智能化的恶意程序检测工具。而机器学习作为人工智能的重要途经,通过将传统方法和机器学习的结合,能够得到性能更加优秀的检测方式。
目前该检测方法上存在可以改进的地方,未来的工作包括使用概率图模型,如:隐马尔可夫模型、话题模型对特征进行进一步的处理,尝试使用更多不同的模型,如:卷积神经网络模型,循环神经网络模型对数据进行学习,以及采用更好的方式模拟人的行为并监控应用程序动态行为特征,在特征向量中加入动态行为特征,进一步提高检测精度。
[1]李航.统计学习方法[M].清华大学出版社:北京,2012:55-58.
[2]周志华.机器学习[M].清华大学出版社:北京,2016:178-181.
[3]阿里云安全恶意程序检测[EB/OL].https://tianchi.aliyun.com/competition/,2020-4-10.
作者简介:吕斌燕(1996-)女,汉族,山西省运城市,现就读于西华大学计算机与软件工程学院研究生,研究方向:机器学习与社会网络。

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



