1.中国农业科学院农业信息研究所,北京 100081; 2.农业农村部农业大数据重点实验室,北京 100081
摘要: 为提高现有苹果目标检测模型在硬件资源受限制条件下的性能和适应性,实现在保持较高检测精度的同时,减轻模型计算量,降低检测耗时,减少模型计算和存储资源占用的目的,本研究通过改进轻量级的MobileNetV3网络,结合关键点预测的目标检测网络(CenterNet),构建了用于苹果检测的轻量级无锚点深度学习网络模型(M-CenterNet),并通过与CenterNet和单次多重检测器(Single Shot Multibox Detector,SSD)网络比较了模型的检测精度、模型容量和运行速度等方面的综合性能。对模型的测试结果表明,本研究模型的平均精度、误检率和漏检率分别为88.9%、10.9%和5.8%;模型体积和帧率分别为14.2MB和8.1fps;在不同光照方向、不同远近距离、不同受遮挡程度和不同果实数量等条件下有较好的果实检测效果和适应能力。在检测精度相当的情况下,所提网络模型体积仅为CenterNet网络的1/4;相比于SSD网络,所提网络模型的AP提升了3.9%,模型体积降低了84.3%;本网络模型在CPU环境中的运行速度比CenterNet和SSD网络提高了近1倍。研究结果可为非结构环境下果园作业平台的轻量化果实目标检测模型研究提供新的思路。
关键词: 机器视觉;深度学习;轻量级网络;无锚点;苹果检测
中图分类号: TP183 文献标志码: A 文章编号: 202001-SA004
引文格式:夏雪, 孙琦鑫, 侍啸, 柴秀娟. 基于轻量级无锚点深度卷积神经网络的树上苹果检测模型[J]. 智慧农业(中英文), 2020, 2(1): 99-110.
Citation:Xia Xue, Sun Qixin, Shi Xiao, Chai Xiujuan. Apple detection model based on lightweight anchor-free deep convolutional neural network[J]. Smart Agriculture, 2020, 2(1): 99-110.
1 引言
智能化栽培和机器化作业是可持续果业发展的有效途径,有利于降低经济和环境成本,提高果园生产率[1,2]。在果园自然环境下,高性能的视觉感知系统是自动化栽培平台进行果实作业的前提和关键,能否快速、准确地检测到果实目标直接影响着果园自动化栽培平台的果实作业效率[3]。
针对果园中果实目标检测问题,许多学者开展了广泛研究。一些研究通过设计手工参数来提取图像中的目标特征,如阈值、掩模、颜色空间、形状、边缘、纹理等普通特征[4-9],以及灰度共生矩阵(Gray-level Co-occurrence Matrix,GLCM)和梯度方向直方图(Histogram of Oriented Gradients,HOG)等特殊特征[10-12]。传统机器学习的方法,如支持向量机(Support Vector Machine,SVM)、人工神经网络(Artificial Neural Network,ANN)等也被证实可以提高果实目标的检测性能[13-17]。尽管上述方法能够检测出图像中的果实,但由于不同光照条件会影响反射光的强度,使这类基于手工设计特征的方法无法保持稳定的检测准确度。虽然人工照明控制技术可以克服光照变化带来的问题[18],但该方法只能在夜间使用,工作时间受到限制,这让果实检测任务变得更加复杂和昂贵。
近年来,深度卷积神经网络(Deep Conv-olutional Neural Network,DCNN)在许多计算机视觉任务(如目标分类[19]和目标检测[20])中都有优异的表现,与传统方法相比具有强大的特征提取能力和自主学习机制,表现出更好的鲁棒性和准确性[21]。DCNN的良好表现使其在农业领域也得到了应用:Sa等[22]采用Faster-RCNN来检测图像中的甜椒,取得了较好的检测效果;Yu等[23]利用Mask-RCNN对温室中的草莓进行检测和分割,用来指导机器人自动采收草莓;陈桂芬等[24]利用数据增强与迁移学习相结合的DCNN实现了玉米植株主要病害的精准识别;为了监测和评估苹果生长情况,Tian等[25]利用DenseNet改进YOLO-v3的低分辨率特征层,实现了对苹果果实的实时检测;Koirala等[26]在重新设计YOLO网络结构的基础上,提出了MangoYOLO网络模型,用于芒果果实检测等。
优秀的深度学习模型需要在处理时间和检出率之间进行权衡。通常模型处理速度越快,检出率越低,这时就需要模型在期望时间周期和检出率之间达到平衡
[27]。锚点(Anchor)的概念在两阶段检测和单阶段检测中均有体现,其主要作用是通过枚举的方式得到符合待处理数据集特性的多尺度边框模板和多个目标长宽比[28]。然而,设计多个锚点并将其分配给特定目标需要大量的实践经验,并且当锚点利用交并比(Intersection-over-Union,IoU)作为主要评判准则来确定检测目标时,不同的IoU阈值会使算法性能产生明显波动。为此,一些利用关键点代替锚点来表示待检测目标的无锚点方法相继提出并受到广泛关注。Law等[29]首次将关键点检测用于目标检测任务上,提出了CornerNet模型,该模型将目标位置检测转化为目标边界框左上角和右下角关键点的检测问题,无需设计锚点,极大地简化了网络的输出,同时在精度上优于基于锚点的单阶段检测器;Duan等[30]构建了基于三元组关键点的物体检测模型,该模型在CornerNet的基础上,加入了一个中心关键点,通过一个中心关键点和一对角点来表示每个物体,从而获取更多的物体内部信息,实现了目标检测精度的提升;不同于CornerNet模型的思路,Zhou等[31]提出的ExtremeNet模型通过标准的关键点估计网络来检测目标的4个极值点(即最上点,最下点,最左点,最右点)和1个中心点,并运用几何关系对关键点进行分组,使得一组极值点(5个点)对应一个检测结果。ExtremeNet使用的基于外观关键点估计的方法省去了区域分类和隐式特征学习的过程,获得了更好的检测效果。
现有基于无锚点的目标检测方法虽然在算法稳定性上得到提升,但由于模型参数过多,对硬件计算资源要求较高,同时较大的模型体积也使其无法适用于硬件资源相对受限的作业平台。为此,本研究基于果园作业平台硬件资源受限的现状,针对算法模型计算负担和模型大小敏感的问题,将轻量级深度卷积神经网络与无锚点目标检测网络结合,构建了一个轻量级无锚点的树上苹果检测网络模型,实现了在保持较高检测精度的同时,减轻模型的计算量,降低模型资源占用的目标,从而满足果园作业平台对于轻量化目标检测模型的需求。
2 材料与方法
2.1 图像数据获取与处理
试验图像数据的采集地点位于中国辽宁省兴城市的苹果园。数据采集设备为手持式数码相机,采集时间为8:00-17:00,在晴朗和多云天气条件下共采集1455幅苹果图像。在采集过程中,相机镜头与果树列平行,并与果树保持50cm左右的距离,该距离利于果园作业平台找到合适的目标搜索区域,方便其高效地完成任务。采集图像的像素分辨率为5472×3648,为减轻计算负担,将采集图像的像素分辨率调整为750×500。同时,运用自主开发的标注工具对所有图像中的苹果进行逐一标注,获取并记录图像中每个苹果标注框的坐标信息,即标注框的左上角和右下角两个点的x、y坐标信息。
2.2 CenterNet网络
CenterNet网络[32]是目前性能最好、最有效的无锚点目标检测网络之一。无锚点目标检测网络中,无论是CornerNet网络将边框两个角点作为检测关键点,还是ExtremeNet算法需要检测出目标的最上、最下、最左、最右和中心五个点,都需要在检测出关键点后对其分组,而这些操作无疑会降低算法整体速度。CenterNet网络提供了一种更为简洁的思路,即通过一个点来定位待检测目标。其网络结构如图1所示。
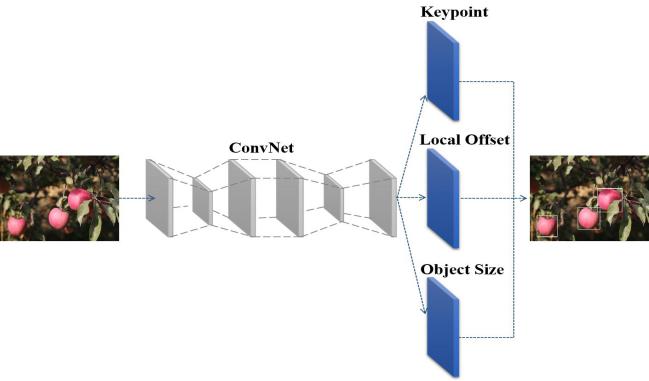
图1 CenterNet网络结构示意图
Fig.1 Network structure diagram of CenterNet
网络模型通过热力图寻找目标中心点,预测每一个像素点是否为物体中心(关键点),在预测时首先要做的是生成关键点热力图(Keypoint Heatmap),分别提取热力图上所有目标的峰值点。其做法是将热力图上的所有响应点与其连接的8个相邻点进行比较,如果该点响应值大于或等于其8个相邻点的值,则保留该点,否则忽略该点,最后保留满足要求的前100个峰值点。令 是检测到的c类别的n个中心点的集合,其中
是检测到的c类别的n个中心点的集合,其中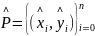 ,每个关键点坐标以整型坐标(xi, yi)的形式给出。
,每个关键点坐标以整型坐标(xi, yi)的形式给出。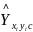 作为关键点测量得到的检测置信度,在每个关键点位置上会产生如式(1)的边界框:
作为关键点测量得到的检测置信度,在每个关键点位置上会产生如式(1)的边界框:
 (1)
(1)
其中,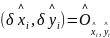 ,为偏移量的预测结果;
,为偏移量的预测结果;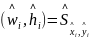 ,是目标尺寸预测结果。所有的预测输出直接来自关键点估计,每个中心点都可以看作是一个单独且形状未知的锚点,只不过这种锚点只和位置有关,不存在锚点的重叠,无需人为设置阈值来进行前景和背景的区分,每个目标只对应一个锚点,无需非极大值抑制(Non-Maximum Suppression,NMS)处理,从而大大减少了网络参数量和计算量。
,是目标尺寸预测结果。所有的预测输出直接来自关键点估计,每个中心点都可以看作是一个单独且形状未知的锚点,只不过这种锚点只和位置有关,不存在锚点的重叠,无需人为设置阈值来进行前景和背景的区分,每个目标只对应一个锚点,无需非极大值抑制(Non-Maximum Suppression,NMS)处理,从而大大减少了网络参数量和计算量。
CenterNet网络输出的三类预测结果可通过图2来描述。其中,图2(a)为Keypoint Heatmap,红色区域为估计的关键点,粉色区域表示以预测关键点为中心的高斯分布区域;图2(b)为预测关键点的偏置(Local Offset),表示标注信息从输入图像映射到输出特征图时由于取正操作带来的坐标误差;图2(c)是预测目标的尺寸(Object Size),即通过预测的目标框宽高和中心点位置获得目标框的位置坐标和大小。

(a) Keypoint heatmap (b) Local offset (c) Object size
图2 CenterNet网络输出三类预测结果示意图
Fig.2 Three prediction outputs types of CenterNet network
2.3 轻量级无锚点的树上苹果检测网络
为了保证果园作业平台的移动灵活性和轻便性,平台通常使用小体积的工控硬件系统,由于这类硬件系统往往计算和存储资源相对缺乏,因此对算法模型的计算负担和模型大小比较敏感,如果使用的深度学习模型参数较多、计算量和体积较大,必将会影响果园作业平台的速度和效率。CenterNet初始使用的骨干网络是用于语义分割的编码解码全卷积网络,虽然可以得到较高的检测精度,但生成的模型由于参数较多,模型体积依然较大,难以用于硬件资源相对有限的果园作业平台。
MobileNetV3网络[33]是在MobileNet和MobileNetV2网络基础上提出的,属于轻量化的卷积神经网络。MobileNetV3结构综合了深度可分离卷积(Depthwise Separable Convolutions,DSC)模块和具有线性瓶颈的反向残差结构,同引入了基于压缩与激励(Squeeze and Excitation,SE)结构的轻量级注意力模块SE-Block。
有别于标准卷积使用多个与输入数据相同深度的卷积核进行卷积求和的过程,DSC则将标准卷积的过程分解成深度卷积和逐点卷积两步来实现,如图3所示。首先进行深度卷积,即对输入数据的每个通道,利用单通道卷积核进行卷积操作;然后进行逐点卷积,即使用N个与输入数据深度相同的1×1卷积核对第一步卷积生成的结果进行再次卷积,组合生成新的结果。DSC最终输出数据的维度与标准卷积的输出维度相同,但计算量会因为这种分解形式的卷积操作而大幅减少[34]。因此,DSC的主要功能是缩减网络的参数,从而加快网络的计算速度。
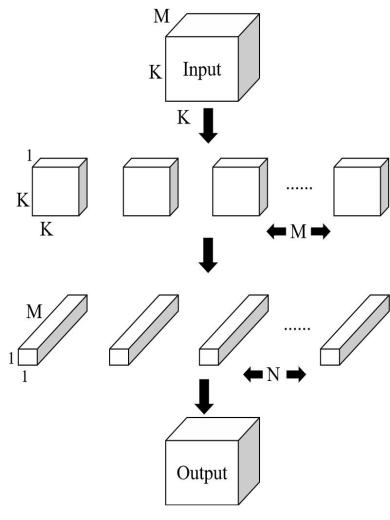
图3 深度可分离卷积结构示意图
Fig.3 Structure diagram of DSC
ResNet中提出的残差网络结构使得神经网络的参数更加有效[35]。ResNet残差单元中对通道维度采用先缩减后扩展的处理顺序。考虑到DSC通常期望在高维度的输入中进行特征提取,因此反向残差对ResNet残差单元做了进一步改进,即先对通道维度进行扩展,经过深度可分离卷积后再缩减通道维度,从而增强模型的表达能力。在通过低维度输出层后,特征信息会更集中在缩减后的通道中,如果后面依然接一个非线性激活函数(例如ReLU6等),会发生较严重的信息丢失,进而影响准确度。 因此,需要在通道维度缩减的瓶颈层,去除1×1卷积后的ReLU6非线性激活函数,变为线性输出[36],形成线性瓶颈结构,从而保证网络提取特征的有效性。
SE-Block的主要功能是利用结合特征通道间的关系,形成让网络模型对特征进行校准的机制,使得网络中有效的特征权重大,无效或效用小的特征权重小,实现注意力(Attention)的效果,从而加强网络的学习能力[37]。MobilenetV3中SE-Block的结构如图4所示。其中,W和H表示特征图的宽和高,C表示特征图通道数,输入特征图大小表示为W×H×C。首先对输入特征图进行压缩(Squeeze)操作,经过压缩操作后,特征图被压缩成1×1×C的向量;然后对特征图进行激励(Excitation)操作,达到限制模型复杂度和辅助泛化的目的;最后对特征图进行重标定(Scale)操作,将Squeeze和Excitation操作后计算出来的各通道权重值分别与原特征图相应通道的二维矩阵相乘,得到最终结果后输出。
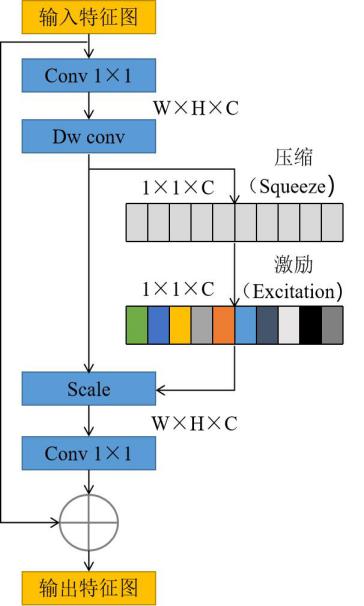
图4 MobileNetV3中SE-Block的结构示意图
Fig.4 Structure diagram of SE-Block in MobileNetV3
MobileNetV3在网络中大量使用了深度可分离卷积和具有线性瓶颈的反向残差结构,利用5×5大小的深度卷积替代网络中部分3×3的深度卷积,大幅减少了模型的参数量和计算开销,同时引入SE-Block以提高模型的精度,从而实现了模型体积、速度与精度的平衡。鉴于MobileNetV3在模型体积和速度上的优势,将其作为本研究网络模型的主干网络,用来提取苹果图像中的有效特征。MobileNetV3网络分为MobileNetV3-Large和MobileNetV3-Small两个版本,其中本研究使用MobileNetV3-Large拥有更深的网络,因此在模型精度上表现更为优异。
为了获取更加有效的特征图用于本研究网络模型的预测,对MobileNetV3网络做了进一步的改进。将网络中最后一个瓶颈(Bottleneck)层后的平均池化层和3个1×1卷积层去除,增加3个上采样转置卷积(Transposed Convolutional)层,用来更好还原图像的语义信息和位置信息。经过转置卷积生成的特征图会被分别送入CenterNet网络的三个子网络做关键点、偏置和尺寸预测。最终形成的网络命名为M-CenterNet,其网络结构如图5所示。

图5 M-CenterNet网络结构示意图
Fig.5 Network structure of M-CenterNet
网络整体的损失函数由目标中心点损失(Lk)、目标中心偏置损失(Loff)与目标大小损失(Lsize)组成,即:
 (2)
(2)
每个损失都有相应的权重。损失函数中,分别设置系数 和
和 来调节Loff和Lsize。本研究中 和 分别设为1和0.1。
来调节Loff和Lsize。本研究中 和 分别设为1和0.1。
对于目标关键点的损失,训练关键点网络时,将Ground Truth的关键点通过如式(3)的高斯核分散到热力图上,
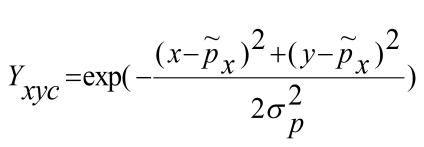 (3)
(3)
其中,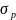 是目标自适应尺度的标准方差;Yxyc是将关键点分散到热力图上的高斯核。目标关键点损失值Lk由像素级逻辑回归的焦点损失(Focal Loss)计算得到,Lk计算公式如式(4)所示。
是目标自适应尺度的标准方差;Yxyc是将关键点分散到热力图上的高斯核。目标关键点损失值Lk由像素级逻辑回归的焦点损失(Focal Loss)计算得到,Lk计算公式如式(4)所示。
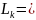
 (4)
(4)
其中,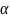 和
和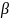 为Focal Loss的超参数,N是图像的关键点数量,用于将所有正的焦点损失(Positive Focal Loss)标准化为1。
为Focal Loss的超参数,N是图像的关键点数量,用于将所有正的焦点损失(Positive Focal Loss)标准化为1。
对于目标中心的偏置损失,由于网络会对输入图像进行下采样操作,所得特征图必然会在重新映射到原图像上时产生精度误差,因此对于图像中每个有效中心点,额外添加一个Local Offset(Loff)来进行补偿。这样,所有类别c的中心点将共享同一个偏移预测值。Loff的偏置值由L1 loss计算得到,即:
![]() (5)
(5)
其中,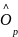 是预测得到的偏置;
是预测得到的偏置;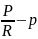 是训练过程中提前计算出来的值。
是训练过程中提前计算出来的值。
对于目标大小的损失,网络通过关键点估计因子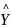 预测图像中所有的中心点,并为每个目标k回归出该目标的尺寸sk,即:
预测图像中所有的中心点,并为每个目标k回归出该目标的尺寸sk,即:
![]() (6)
(6)
为了减少目标尺寸的回归难度,使用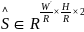 作为预测值,并采用L1 loss来监督回归目标的h和w。目标大小的损失值Lsize由式(7)计算得到
作为预测值,并采用L1 loss来监督回归目标的h和w。目标大小的损失值Lsize由式(7)计算得到
![]() (7)
(7)
3 试验结果与分析
3.1 试验软硬件环境
本研究试验运用深度学习框架进行模型训练和测试,因此选用图形工作站作为硬件平台,硬件配置为Intel Core i7-7700 CPU处理器,32GB内存,NVIDIA TITAN Xp型GPU显卡(16GB),操作系统为Linux Ubuntu 16.04,并行计算框架为CUDA 10.0,深度神经网络加速库为CUDNN 7.5,使用python编程语言在Pytorch 1.0深度学习框架下实现本文网络模型的构建、训练和验证。
3.2 模型训练
网络模型在带有GPU的硬件环境下进行训练,以提高模型训练的收敛速度。采用带动量因子(Momentum)的小批量(Mini-batch)随机梯度下降法(Stochastic Gradient Descent,SGD)来训练网络。其中,每一批量图像样本数量(Batch size)设置为16,动量因子设为固定值0.9,权值衰减(Decay)为5×10-4。权重的初始化会影响网络训练的收敛速度,因此本试验中采用均值为0、标准偏差为0.001的高斯分布对网络每一层的权重进行随机初始化。所有卷积层和反向卷积层的偏置(Bias)值均初始化为0。对网络中的所有层采用相同的学习速率,初始学习速率(Learning Rate)设为1.25×10-4,训练过程中,当验证集的检测精度停止增加时,则使用余弦退火(Cosine Annealing)的方式将学习速率降低为当前学习速率的10%,直到通过调整学习速率不再提高验证集的检测精度为止。同时,使用在线数据增强的方法对数据进行光度扭曲和随机抽样。
网络模型使用1455幅苹果图像数据作为样本,按照8 :1 :1 的比例分配训练集、验证集和测试集,即训练集1164幅、验证集146幅、测试集145幅。由于试验中采用COCO数据格式[38]进行训练,因此在训练模型前需将数据集信息转换成*.json格式的数据文件。最终网络模型一共迭代训练140次,耗时44min,其Loss值随迭代次数的变化如图6所示。
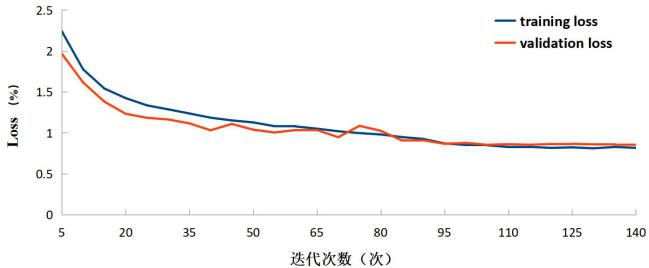
图6 Loss值随迭代次数的变化曲线图
Fig.6 Curve of the Loss value changing with the number of iterations
由图6可以看出,模型在前30次迭代中迅速拟合,Loss值快速降低,随后降低幅度逐渐缩小,在90次后渐渐稳定,只有较少的震荡。随着网络模型训练迭代次数的不断增加,训练集和验证集的Loss差距逐渐减小,当网络训练迭代次数达到85次时,网络对训练集和验证集的Loss都降至1以下,且从第90次迭代以后,训练集和验证集的Loss差值相差不大,Loss基本收敛到稳定值,表明网络模型已经达到了预期的训练效果。
3.2 试验结果与性能评价
3.2.1 试验结果
在果园作业平台实际工作中,平台移动会使图像采集环境发生变化。因此,试验分别选取测试集中不同光照方向、不同远近距离、不同遮挡程度和不同果实数量的苹果图像送入训练好的网络模型,对图像中的树上苹果进行自动检测并记录结果,以评价网络模型在不同条件下的检测能力。
果园中光照的变化会产生图像欠曝光或过曝光的现象,使图像中的果实偏暗或过亮。试验发现,本研究网络模型对不同光照条件下的苹果检测有较好的鲁棒性,如图7所示。

图7 不同光照情况的检测效果图
Fig.7 Detection results of different illumination conditions
模型中的深度卷积神经网络具有较强的特征提取能力,能够根据不同苹果图像,自主提取不同特点的特征进行学习,从而克服因光照变化导致的过暗或过亮苹果目标无法较好检测的问题。
摄像头与果实间的距离差异,会让图像中果实的尺寸产生差异。摄像头与果实间的距离越远,图像中的果实尺寸越小。因此,按照果实目标的距离远近,将果实图像分为3种情况,即果实距离较近、果实距离适中和果实距离较远,如图8所示。通过对比可知,较近距离果实图像和适中距离果实图像中果实尺寸较大,目标较为清晰完整,可用信息较多,因此能有较好的检测效果,如图8(a)、图8(b)所示。较远距离果实图像中,苹果目标的尺寸相对较小,其携带的信息也相对减少,因此产生了一定漏检和预测框偏移的情况,如图8(c)所示。

图 8 不同远近距离的果实检测效果图
Fig.8 Results of fruit detection in different
distance conditions
由于果树生长的随机性,在园间拍摄的苹果图像中果实并非是全部独立可见的,会产生果实被枝叶遮挡或果实相互遮挡的情况,这在一定程度上会增加果实检测的难度。因此,对比不同遮挡程度下的果实检测效果,以评价所提模型的环境适应性。结果发现,受遮挡后果实外露面积大于整个果实面积1/2时,所提模型对苹果目标的检测效果较好,如图9所示。针对枝叶遮挡使单个果被分成多个部分的情况,本研究模型仍能完整的检测出被枝叶遮挡分成多个部分的果实目标。同时,针对多果连续重叠遮挡的情况,本研究模型也能够逐一检测出每个受遮挡的果实目标。说明本模型对于果实受遮挡的情况具有一定的抗干扰能力。
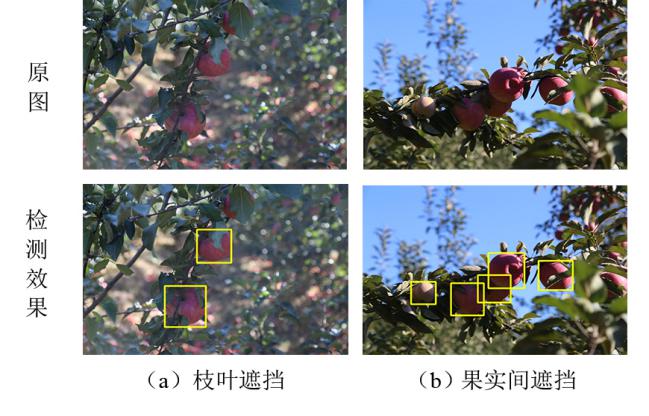
图9 果实受遮挡后的检测效果图(果实外露面积大于整个果实面积的1/2)
Fig.9 Detection results of partly obscured apples(the exposed area of the apple is greater than 1/2 of its total area)
随着果实受遮挡面积的增大,果实外露面积相对减少,会使果实检测的效果降低。当受遮挡后果实外露面积小于整个果实面积1/3时,由于枝叶严重遮挡使得模型无法提取出足够的果实特征图信息,会出现果实目标没有被检测到的情况,如图10所示。同时,果实相互间被严重遮挡时,会对热力图目标中心点预测的结果产生影响,导致一些被遮挡果被检测模型视为同一个果实,如图11所示。
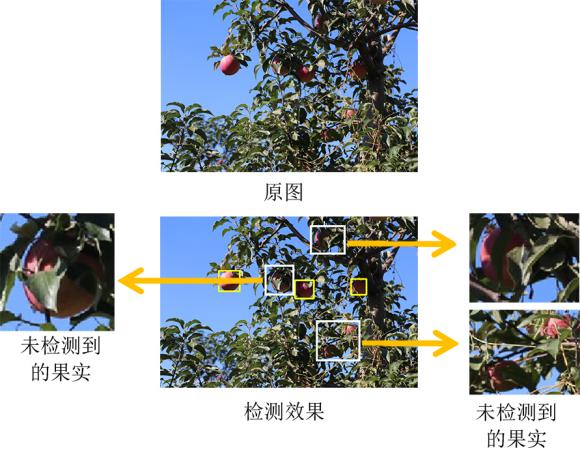
图10 枝叶严重遮挡情况下的检测效果图(果实外露面积小于整个果实面积的1/3)
Fig.10 Detection results of apples occluded severely by branches and leaves (the exposed area of the apple is less than 1/3 of its total area)

图11 果实间严重遮挡情况下的检测效果图(果实外露面积小于整个果实面积的1/3)
Fig.11 Detection results of fruits occluded severely by other fruits (the exposed area of the apple is less than 1/3 of its total area)
通过对比不同果实数量图像的检测效果可知,果实数量的增加并不会直接影响模型的目标检测效果,如图12所示,但多果或密集果图像中,果实间严重重叠遮挡的情况增多,这会在一定程度上影响果实检测效果。
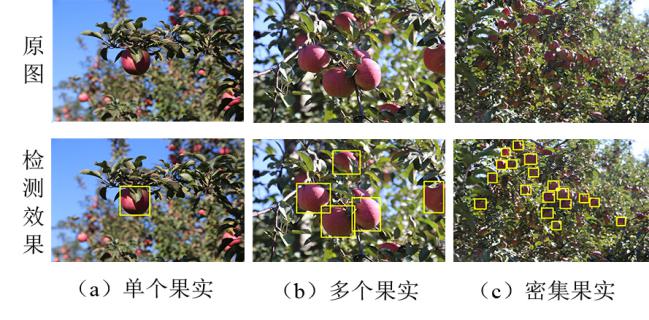
图12 不同果实数量的检测效果图
Fig.12 Results of fruit detection of different quantities
3.2.2 性能评价
网络模型的检测精度决定着果园栽培平台能否成功对果实实施园艺作业,通常模型检测精度越高,果实作业成功率越高,同时,较小的模型容量意味着更小的硬件计算和存储资源占用,也更容易移植到硬件资源有限的果园作业平台中应用,而较快的模型运行速度代表着模型能够在更短时间内处理更多数据,也更加能满足果园栽培平台高效园艺作业的需求。鉴于此,分别从网络模型的检测精度、模型容量和运行速度三个维度来定量评价模型的综合性能。同时,将本网络模型与CenterNet和SSD等网络模型进行对比分析。
本研究选取平均精度、误检率和漏检率作为网络模型检测精度的评价指标,它们能够很好地反映网络模型的目标检测能力。模型参数量和模型体积能够较好反映模型对硬件计算和存储资源的占用情况,因此将它们作为模型容量的评价指标。表1给出了不同网络模型的检测精度和模型容量对比情况。
表 1 不同网络模型的检测精度和模型容量对比
Table 1 Comparison of the detection accuracies and volumes of different network models
检测指标 | |||||
检测精度 | 模型容量 | ||||
平均 精度 (%) | 误检率(%) | 漏检率(%) | 模型 体积 (MB) | 参数量 (个) | |
SSD | 85.0 | 14.9 | 12.4 | 90.6 | 23.7×106 |
CenterNet | 88.3 | 11.9 | 7.3 | 60.3 | 15.8×106 |
M-CenterNet | 88.9 | 10.9 | 5.8 | 14.2 | 33.5×105 |
由表1数据可知,本研究提出的M-CenterNet网络的误检率和漏检率分别为10.9%、5.8%,均优于其他两类网络模型。其中,在误检率方面分别比SSD和CenterNet网络模型低4%和1%;同时,在漏检率方面分别比SSD和CenterNet网络模型低6.6%和1.5%,说明所提网络模型能够较好地分辨出果实目标和背景。通过对比不同网络模型发现,SSD、CenterNet和本研究的M-CenterNet网络模型的平均精度均在85%以上。其中本研究所提的M-CenterNet网络模型和CenterNet网络模型由于使用了中心点预测策略来检测苹果目标,因此两个网络模型的平均精度值非常接近,M-CenterNet网络模型略高于CenterNet网络模型0.6%。基于锚点策略的SSD网络模型的平均精度值最低,比本研究提出的M-CenterNet网络模型低了3.9%,表明所提网络模型在平均精度上更具优势,能够更加准确地检测出图像中的果实目标。
从表1数据可以看出,模型的参数量与模型体积成正比,即参数量越多,模型体积越大,反之亦然。本研究提出的M-CenterNet网络模型由于利用了深度分离卷积和逐点卷积,使卷积计算量和模型参数量大幅减少,模型参数量仅为33.5×105,分别比CenterNet和SSD模型低了4.7倍和7.0倍。本研究网络模型的体积为14.2MB,是SSD模型体积的15.6%、CenterNet模型体积的23.5%,更少的参数量带来了更小的模型体积。
除了评估网络模型的检测精度和模型容量情况外,本研究还对网络模型目标检测的运行速度做进一步的测试,以评估网络模型是否能够满足果园作业平台户外高效作业的实际需求。考虑到苹果检测系统需要搭载到果园作业平台的工控机中使用,而大多数情况下工控机只配置CPU处理器,不具有GPU加速计算环境,这就要求模型能在CPU环境下高效地完成苹果检测任务。鉴于此,本研究重点在CPU环境下测试模型的时间性能。检测耗时(分为总耗时和单帧耗时)和帧率能够较好反映模型对于批量数据的检测速度和单位时间内的检测速度,因此将它们作为模型运行速度的评价指标,结果如表2所示。
表2 不同网络模型的运行速度对比
Table 2 Running speed comparison of different network models
总耗时(s) | 单帧耗时(ms) | 帧率(fps) | |
SSD | 35.0 | 241.5 | 4.1 |
CenterNet | 30.9 | 212.8 | 4.7 |
M-CenterNet | 17.8 | 123.0 | 8.1 |
由表2可知,本研究的M-CenterNet网络模型在CPU环境下与CenterNet和SSD网络模型相比有比较明显的运行速度优势,总耗时分别快3.4s和4.0s;单帧耗时分别快89.8ms和118.1ms,处理速度快了近50%。表明本研究模型在CPU环境下,能够更加快速的完成苹果目标检测任务。
本研究网络模型在运行速度上的较好表现得益于网络中的无锚点检测策略和深度可分离卷积的轻量级模块,在CPU条件下深度可分离卷积比普通卷积的计算速度更快,同时无锚点的检测策略省去了NMS等操作,使得整个网络的推断时间大幅缩短,检测速度得以提升。
4 结论
针对果园自然环境下苹果目标的视觉检测任务,提出了一种基于轻量级无锚点的树上苹果检测网络模型。通过改进CenterNet网络模型的特征提取网络,使用更加轻量化的MobileNetV3网络进行特征提取,并引入转置卷积获取更加有效的特征图,从而在苹果目标检测精度、模型容量以及运行速度上实现网络模型性能的综合提升。试验结果表明,本研究的M-CenterNet网络模型能够较好分辨出果实目标和背景,其误检率和漏检率分别为10.9%、5.8%,优于SSD和CenterNet网络模型;本研究网络模型的平均精度和模型体积分别为88.9%、14.2MB,相比于SSD网络模型,分别高了3.9%和降低了84.3%;相比于CenterNet网络模型,在检测精度相当的情况下,本研究提出的M-CenterNet网络模型的体积仅为CenterNet网络模型的1/4;本研究网络模型的帧率为8fps,相较于CenterNet和SSD网络模型,该模型在CPU环境下的运行速度提升了近1倍。
本研究的M-CenterNet网络模型在保持较高检测精度前提下,计算和存储资源占用更低、模型轻量化程度更高,且在硬件资源受限条件下检测速度更快,适合在户外果园移动作业平台上部署。在下一步的研究工作中,将继续改进模型,增加学习样本数量,探索更多方法优化苹果目标的检测性能,并在嵌入式设备中做进一步测试。
参考文献
[1] Kang H, Chen C. Fruit detection and segmentation for apple harvesting using visual sensor in orchards[J]. Sensors, 2019, 19(20): 4599-4614.
[2] 王丹丹, 何东健. 基于R-FCN深度卷积神经网络的机器人疏果前苹果目标的识别[J]. 农业工程学报, 2019, 35(3): 156-163.
Wang D, He D. Recognition of apple targets before fruits thinning by robot based on R-FCN deep convolution neural network[J]. Transactions of the CSAE, 2019, 35(3): 156-163.
[3] 赵德安, 吴任迪, 刘晓洋,等. 基于YOLO深度卷积神经网络的复杂背景下机器人采摘苹果定位[J]. 农业工程学报, 2019, 35(3): 164-173.
Zhao D, Wu R, Liu X, et al. Apple positioning based on YOLO deep convolutional neural network for picking robot in complex background[J]. Transactions of the CSAE, 2019, 35(3): 164-173.
[4] Gené-Mola J, Vilaplana V, Rosell-Polo J R, et al. Multi-modal deep learning for Fuji apple detection using RGB-D cameras and their radiometric capabilities[J]. Computers and Electronics in Agriculture, 2019, 162: 689-698.
[5] Underwood J P, Hung C, Whelan B, et al. Mapping almond orchard canopy volume, flowers, fruit and yield using LiDAR and vision sensors[J]. Computers and Electronics in Agriculture, 2016, 130: 83-96.
[6] Bargoti S, Underwood J P. Image segmentation for fruit detection and yield estimation in apple orchards[J]. Journal of Field Robotics, 2017, 34(6): 1039-1060.
[7] Silwal A, Gongal A, Karkee M. Apple identification in field environment with over the row machine vision system[J]. Agricultural Engineering International: CIGR Journal, 2014, 16(4): 66-75.
[8] Wachs J P, Stern H I, Burks T, et al. Low and high-level visual feature-based apple detection from multi-modal images[J]. Precision Agriculture, 2010, 11(6): 717-735.
[9] Qureshi W S, Payne A, Walsh K B, et al. Machine vision for counting fruit on mango tree canopies[J]. Precision Agriculture, 2017, 18(2): 224-244.
[10] Zhou R, Damerow L, Sun Y, et al. Using colour features of cv.‘Gala’ apple fruits in an orchard in image processing to predict yield[J]. Precision Agriculture, 2012, 13(5): 568-580.
[11] Wang Q, Nuske S, Bergerman M, et al. Automated crop yield estimation for apple orchards[C]// Experimental Robotics. Heidelberg: Springer, 2013: 745-758.
[12] Xiong J, Liu Z, Lin R, et al. Green grape detection and picking-point calculation in a night-time natural environment using a charge-coupled device (ccd) vision sensor with artificial illumination[J]. Sensors, 2018, 18(4): 969-986.
[13] Wang D, He D, Song H, et al. Combining SUN-based visual attention model and saliency contour detection algorithm for apple image segmentation[J]. Multimedia Tools and Applications, 2019, (78): 17391-17411.
[14] Gongal A, Amatya S, Karkee M, et al. Sensors and systems for fruit detection and localization: A review[J]. Computers and Electronics in Agriculture, 2015, 116: 8-19.
[15] Song Y, Glasbey C A, Horgan G W, et al. Automatic fruit recognition and counting from multiple images[J]. Biosystems Engineering, 2014, (118): 203-215.
[16] Luo L, Tang Y, Zou X, et al. Robust grape cluster detection in a vineyard by combining the AdaBoost framework and multiple color components[J]. Sensors, 2016, 16(12): 2098-2118.
[17] Wang C, Lee W S, Zou X, et al. Detection and counting of immature green citrus fruit based on the local binary patterns (lbp) feature using illumination-normalized images[J]. Precision Agriculture, 2018, 19(6): 1062-1083.
[18] Guo Q, Chen Y, Tang Y, et al. Lychee fruit detection based on monocular machine vision in orchard environment[J]. Sensors, 2019, 19: no.4091.
[19] Kestur R, Meduri A, Narasipura O. MangoNet: A deep semantic segmentation architecture for a method to detect and count mangoes in an open orchard[J]. Engineering Applications of Artificial Intelligence, 2019, 77: 59-69.
[20] Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, inception-resnet and the impact of residual connections on learning[C]// Thirty-First AAAI Conference on Artificial Intelligence, 2017: 1-12.
[21] Liu W, Wang Z, Liu X, et al. A survey of deep neural network architectures and their applications[J]. Neurocomputing, 2017, 234: 11-26.
[22] Sa I, Ge Z, Dayoub F, et al. Deepfruits: a fruit detection system using deep neural networks[J]. Sensors, 2016, 16(8): 1222-1245.
[23] Yu Y, Zhang K, Yang L, et al. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN[J]. Computers and Electronics in Agriculture, 2019, (163): 104846-104855.
[24] 陈桂芬, 赵姗, 曹丽英, 等. 基于迁移学习与卷积神经网络的玉米植株病害识别[J]. 智慧农业, 2019, 1(2): 34-44.
Chen G, Zhao S, Cao L, et al. Corn plant disease recognition based on migration learning and convolutional neural network[J]. Smart Agriculture, 2019, 1(2): 34-44.
[25] Tian Y, Yang G, Wang Z, et al. Apple detection during different growth stages in orchards using the improved YOLO-V3 model[J]. Computers and Electronics in Agriculture, 2019, (157): 417-426.
[26] Koirala A, Walsh K B, Wang Z, et al. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’[J]. Precision Agriculture, 2019, (20): 1107-1135.
[27] Williams H A M, Jones M H, Nejati M, et al. Robotic kiwifruit harvesting using machine vision, convolutional neural networks, and robotic arms[J]. Biosystems Engineering, 2019, (181): 140-156.
[28] Wang D , Zhang N , Sun X , et al. AFP-Net: Realtime Anchor-Free Polyp Detection in Colonoscopy[C]// 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 2019.
[29] Law H, Deng J. Cornernet: Detecting objects as paired keypoints[C]// Proceedings of the European Conference on Computer Vision (ECCV), 2018: 734-750.
[30] Duan K, Bai S, Xie L, et al. Centernet: Keypoint triplets for object detection[C]// Proceedings of the IEEE International Conference on Computer Vision. 2019: 6569-6578.
[31] Zhou X, Zhuo J, Krahenbuhl P. Bottom-up object detection by grouping extreme and center points[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 850-859.
[32] Zhou X, Wang D, Krähenbühl P. Objects as Points[J]. Cornell University, 2019, arXiv: 1904. 07850.
[33] Howard A, Sandler M, Chu G, et al. Searching for mobilenetv3[J]. Cornell University, 2019, arXiv: 1905. 02244.
[34] 郑冬, 李向群, 许新征. 基于轻量化 SSD 的车辆及行人检测网络[J]. 南京师大学报 (自然科学版), 2019, 42(1): 73-81.
Zheng D, Li X, Xu X. Vehicle and pedestrian detection model based on lightweight SSD[J]. Journal of Nanjing Normal University (Natural Science Edition). 2019, 42(1): 73-81.
[35] 白傑, 郝培涵, 陈思汉. 用轻量化卷积神经网络图像语义分割的交通场景理解[J]. 汽车安全与节能学报, 2018, 9(4): 433-440.
Bai J, Hao P, Chen S. Traffic scene understanding using image semantic segmentation with an improved lightweight convolutional-neural-network[J]. Journal of Automotive Safety and Energy. 2018, 9(4): 433-440.
[36] 毕鹏程, 罗健欣, 陈卫卫. 轻量化卷积神经网络技术研究[J]. 计算机工程与应用, 2019, 55(16): 25-35.
Bi P, Luo J, Chen W. Research on lightweight convolutional neural network technology[J]. Computer Engineering and Applications. 2019, 55(16): 25-35.
[37] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 7132-7141.
[38] Lin T Y, Maire M, Belongie S, et al. Microsoft coco: common objects in context[C]// European Conference on Computer Vision. Springer, Cham, 2014: 740-755.
Apple detection model based on lightweight anchor-free deep convolutional neural network
Xue Xia1,2, Qixin Sun1,2, Xiao Shi1,2, Xiujuan Chai1,2*
(1.Agricultural Information Institute, Chinese Academy of Agricultural Sciences, Beijing
100081, China;
2.Key Laboratory of Agricultural Big Data, Ministry of Agriculture and Rural Affairs, Beijing 100081, China)
Abstract: Intelligent production and robotic oporation are the efficient and sustainable agronomic route to cut down economic and environmental costs and boosting orchard productivity. In the actual scene of the orchard, high performance visual perception system is the premise and key for accurate and reliable operation of the automatic cultivation platform. Most of the existing apple detection models, however, are difficult to be used on the platforms with limited hardware resources in terms of computing power and storage capacity due to too many parameters and large model volume. In order to improve the performance and adaptability of the existing apple detection model under the condition of limited hardware resources, while maintaining detection accuracy, reducing the calculation of the model and the model computing and storage footprint, shorten detection time, this method improved the lightweight MobileNetV3 and combined the object detection network which was based on keypoint prediction (CenterNet) to build a lightweight anchor-free model (M-CenterNet) for apple detection. The proposed model used heatmap to search the center point (keypotint) of the object, and predict whether each pixel was the center point of the apple, and the local offset of the keypoint and object size of the apple were estimated based on the extracted center point without the need for grouping or Non-Maximum Suppression (NMS). In view of its advantages in model volume and speed, improved MobileNetV3 which was equipped with transposed convolutional layers for the better semantic information and location information was used as the backbone of the network. Compared with CenterNet and SSD (Single Shot Multibox Detector), the comprehensive performance, detection accuracy, model capacity and running speed of the model were compared. The results showed that the average precision, error rate and miss rate of the proposed model were 88.9%, 10.9% and 5.8%, respectively, and its model volume and frame rate were 14.2MB and 8.1fps. The proposed model is of strong environmental adaptability and has a good detection effect under the circumstance of various light, different occlusion, different fruits’ distance and number. By comparing the performance of the accuracy with the CenterNet and the SSD models, the results showed that the proposed model was only 1/4 of the size of CenterNet model while has comparable detection accuracy. Compared with the SSD model, the average precision of the proposed model increased by 3.9%, and the model volume decreased by 84.3%. The proposed model runs almost twice as fast using CPU than the CenterNet and SSD models. This study provided a new approach for the research of lightweight model in fruit detection with orchard mobile platform under unstructured environment.
Key words: machine vision; deep learning; lightweight network; anchor-free; apple detection
收稿日期:2020-01-21 修订日期:2020-02-19
基金项目:国家自然科学基金面上项目(61976219);中国农业科学院农业信息研究所基本科研业务费项目(JBYW-AII-2019-18);中国农业科学院科技创新工程项目(CAAS-ASTIP-2016-AII)
作者简介:夏 雪(1983-),男,博士,助理研究员,研究方向:果树表型研究与应用,Email:xiaxue@caas.cn。
* 通讯作者:柴秀娟(1978-),女,博士,研究员,研究方向:机器视觉、智能感知、农业机器人,电话:13911671540,Email: chaixiujuan@caas.cn。
doi: 10.12133/j.smartag.2020.2.1.202001-SA004


客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



